

Microsoft’s VALL-E AI can imitate any speech with just a brief audio sample, and that’s incredible yet curious!
The company has recently launched this model for text-to-speech AI that can also maintain the emotional and auditory surroundings of the speaker, becoming a real SF thing.
Discover more about VALL-E below and learn how it really works.
VALL-E is the Future
Microsoft has come up with VALL-E, a pretty intriguing model for text-to-speech AI that can do some SF things, including imitating someone’s voice using just a brief audio sample of three seconds. Quite impressive, isn’t it?!
According to the company, the speech could also be tailored to match the speaker’s timbre, the acoustics of a place, and even the emotional tone. Though like deepfakes, there is a danger of abuse, it could one day be employed for specialized or high-end text-to-speech applications.
And there’s more.
The developers explained how they actually trained VALL-E on 60,000 hours of English language speech from 7,000+ people (can you imagine that?!). As a result, the voice it tries to imitate must closely resemble a voice from the training set.
Moreover, VALL-E makes an assumption based on training data about how the target speaker would sound if speaking the intended text input. Check out below how it works:
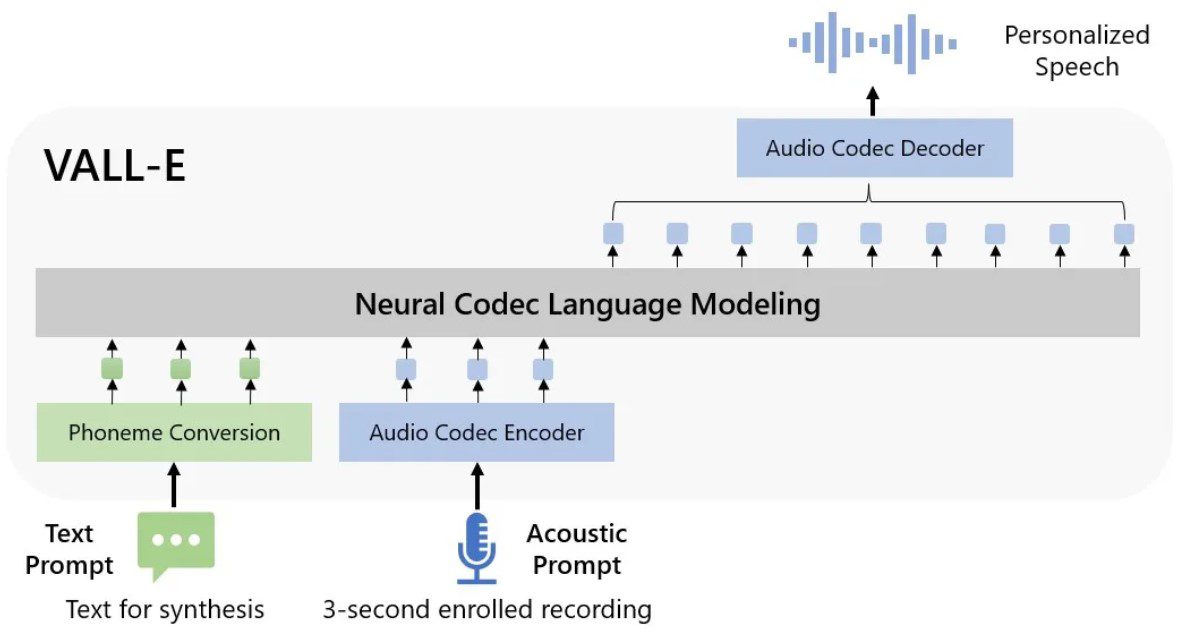
Microsoft refers to VALL-E as a “neural codec language model.” What does it mean?
That represents an offshoot of Meta’s AI-driven compression neural net encoder, which further creates audio from text input and brief samples from the target speaker.
Microsoft intends to increase the model’s training data size in order to “enhance model performance across prosody, speaking style, and speaker similarity perspectives.” It is also looking into methods to cut down on terms that are missing or ambiguous, so in the future, we’ll get the best version of it!